不知大家是否有遇到过这样的问题?我们要调其他系统推送数据,对方接口改了参数要围着对方转,配合调试和测试;调第三方接口经常调不通;每次大促系统都处于崩溃的边缘,如 618、双十一、秒杀活动等。这时候使用 MQ 就可以轻松解决这些问题。
一、MQ 的应用场景
MQ 的应用场景比较多,但是比较核心的应用场景是:解耦、异步、削峰。
1、解耦
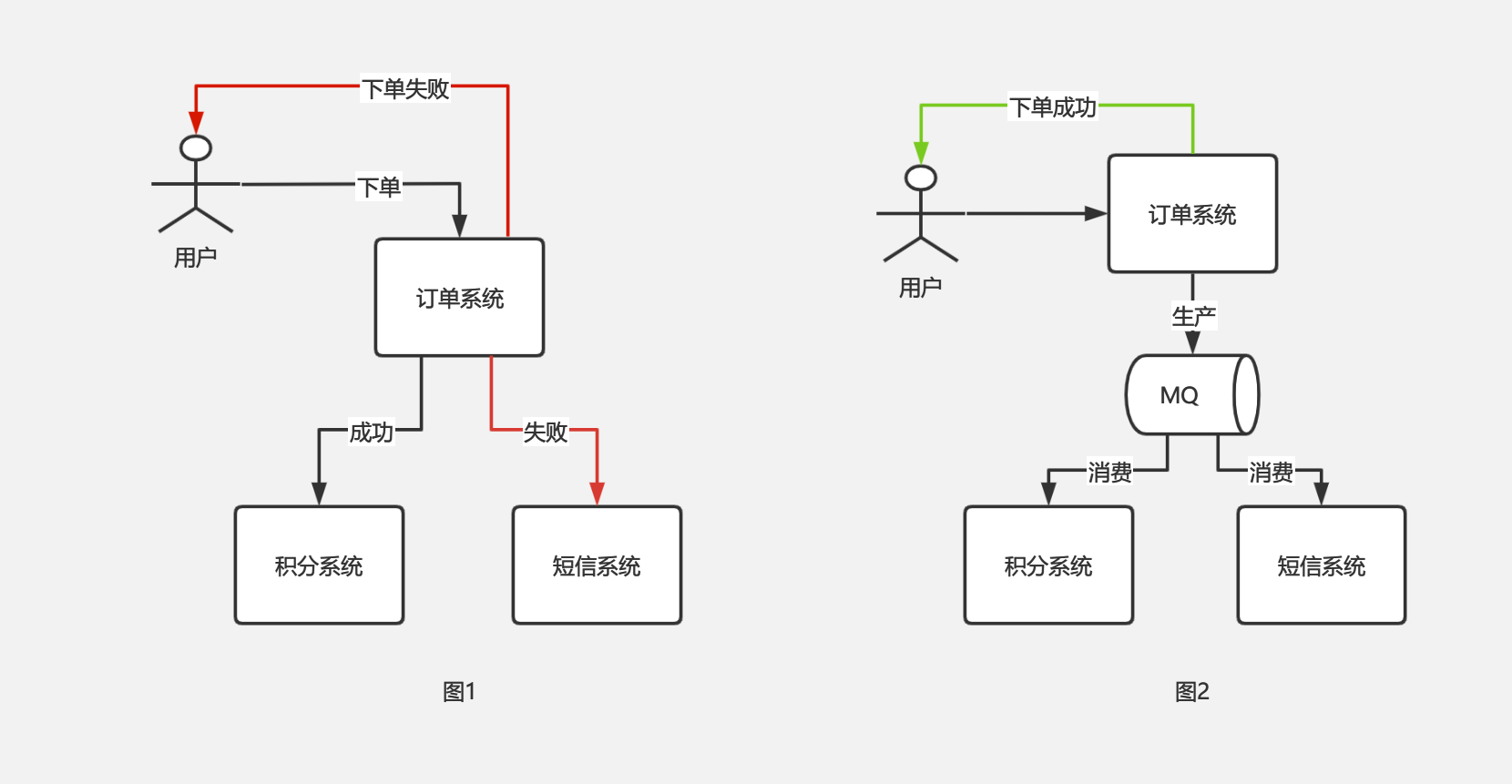
应用解耦场景一:比如订单系统,下单后需要调配送系统通知发货、调积分系统增加积分等。正常情况下,需要在下单完成后手动写代码调用这些接口,如果某个系统调用失败,则下单失败。这时这些系统是耦合在一起的,其中一个系统出故障,会导致整个下单失败。
如果引入 MQ,下单后,把数据推送到 MQ 中,由配送系统、短信系统自己拉取数据进行消费,这时订单系统和配送系统、短信系统就解耦开了,这两个系统的故障也不会影响到下单的过程,下单后直接给用户返回下单成功。如下图 1、图 2 分别为解耦前后的情况。
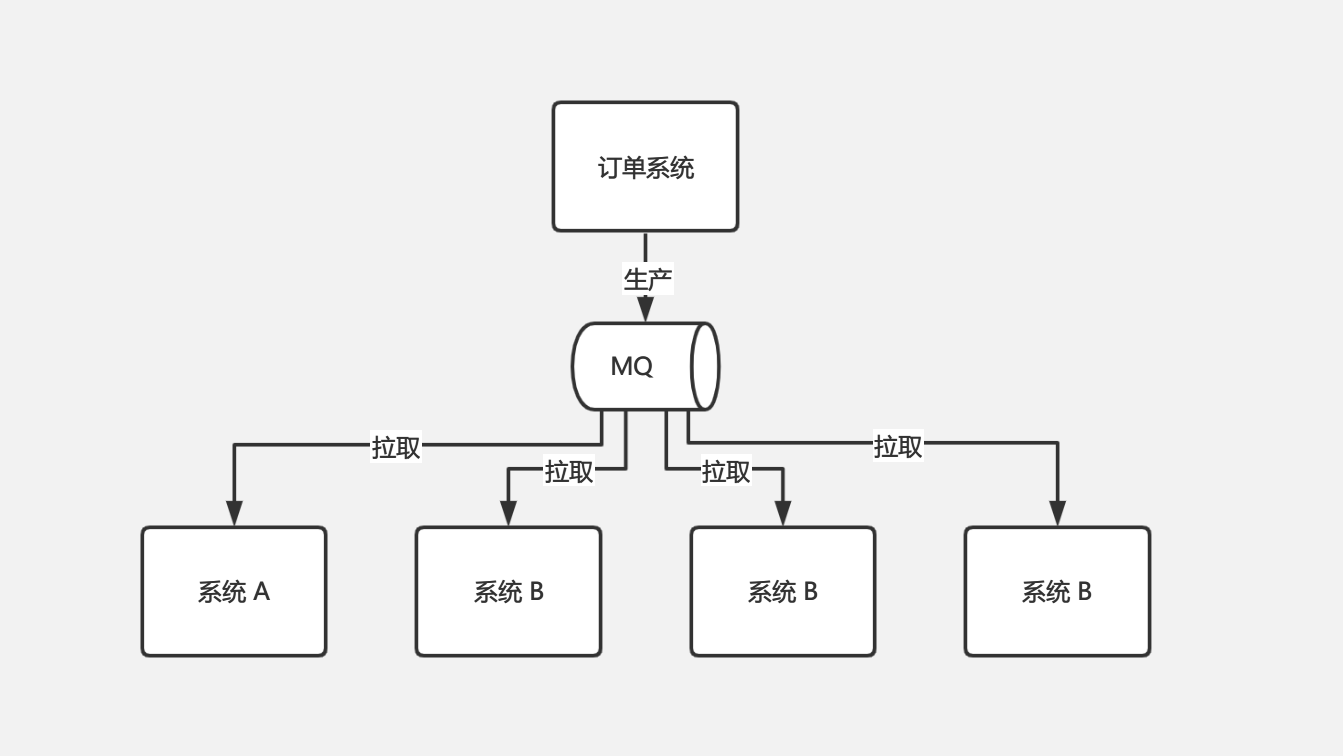
解耦场景 2:还是订单系统,用户下单后,需要推送订单数据给其他部门系统(如大数据部门)做一些如统计分析类的工作。正常情况下也是需要再下单完成之后,给其他系统推送订单数据,这也会有一些问题,比如大数据部门需要增删传输的数据字段、其他部门也需要这个订单数据、某个部门突然又不需要这些数据了,这些操作都需要修改代码才能实现,就跟其他系统耦合在一起了。
引入 MQ 后,就不在需要订单系统主动调其他系统的接口推送数据了,订单系统只需要把数据推送到 MQ 中,其他哪些部门哪些系统需要订单数据,自己编写代码去 MQ 拉取即可。如下图:
2、异步
不知道大家有没有调用过第三方的系统,有过经验的童鞋都知道,说起第三方系统脑海里想到的一个字就是:坑!你永远不知道它啥时候就挂了,也不知道啥时候响应就会慢得跟蜗牛一样,稳定性实在是不好吐槽,五味杂陈啊。
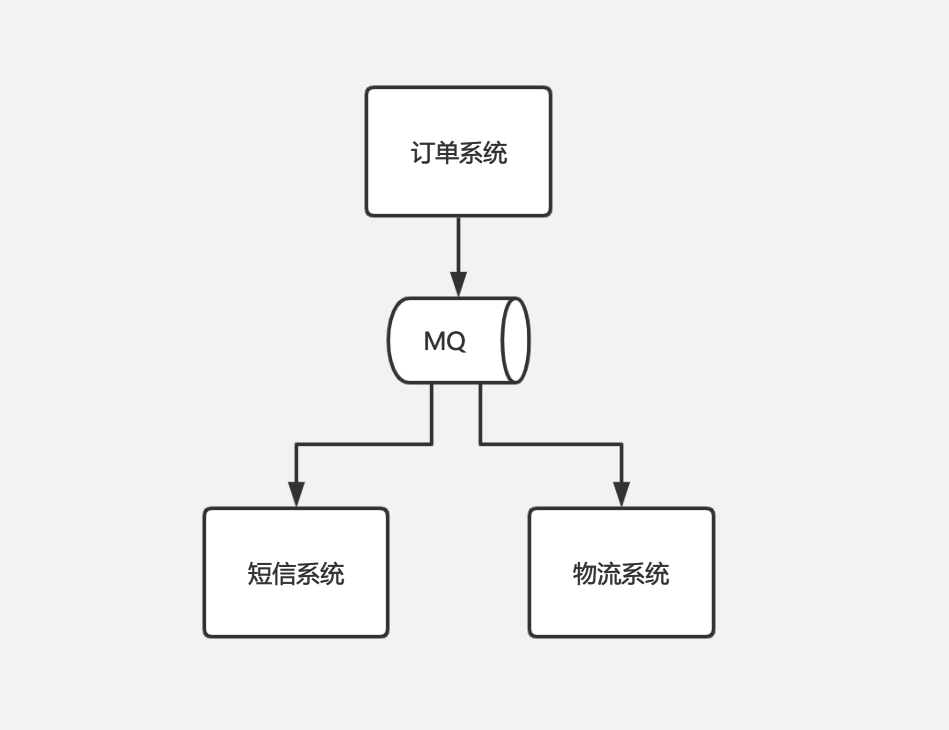
就好像订单系统,你的短信发送功能是第三方短信系统提供的,发货功能是第三方物流系统提供的。当接口故障的时候你需要自己编写复杂的重试逻辑,不管你是同步还是异步调用;重试失败后还要把数据持久化下来,用定时任务在未来某个时间重新推送,因为可能只是当时人家系统刚好不可用了,过个半小时一小时系统恢复了,那你还是需要重新推送的。这一整个逻辑是会复杂,还会影响性能。
如果引入 MQ,那么我们只需把消息推送到 MQ 中,再从 MQ 中消费即可。如果接口不可用,直接给 MQ 返回消费失败,下次还可以重新拉取消息进行消费,不再需要手动编写复杂的重试代码等。如下图
3、削峰
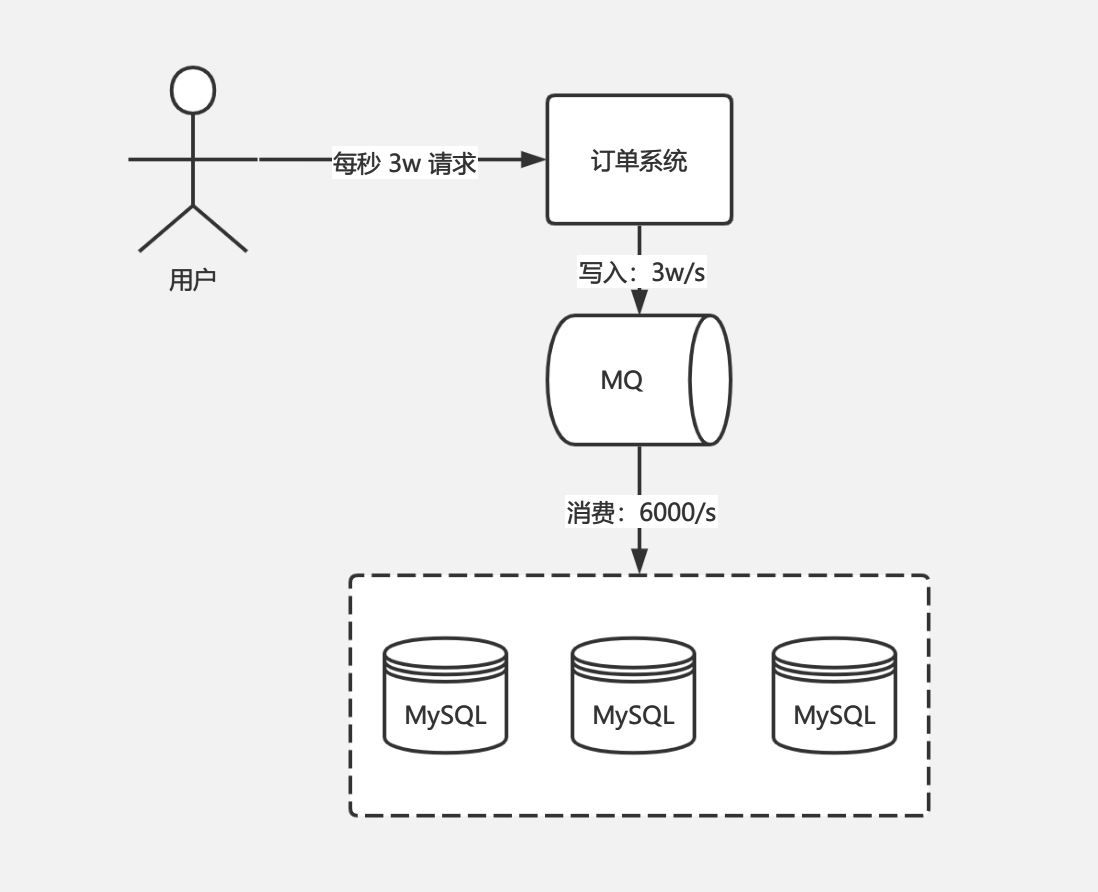
多数情况下,系统的瓶颈都会在数据库,假设数据库每秒可以支撑 6000 个请求,在一些如秒杀、双十一等高峰期场景中,每秒的请求达到了 3W,那么这时数据库是扛不住这么高的并发的,而 MQ 一般抗住几万的并发没有任何问题。
这时我们就可以引入 MQ,请求到达后先写入 MQ 中,再从 MQ 中慢慢消费消息落库,此时写入 MQ 的请求仍然是每秒 3W,但是从 MQ 消费的消息控制在每秒 6000,积压的请求可以在后面空闲期慢慢消费完成。这样,每秒 3W 的请求也可以扛下来,如下图
二、消息队列有什么优缺点?
优点这里应该不用说了吧,就是前面提到的解耦、异步、削峰。
通常来说,应用一项技术,解决了一些问题的同时,也必然会引出其他的新的问题。只不过解决新问题会比旧问题更容易些,也就是新技术的引用是利大于弊的。引入 MQ,也同样会导致一些问题,它的缺点有以下几个:
- 系统可用性降低
我们知道,系统引入的外部依赖越多,就越容易挂掉。你看啊,本来你有 ABCD 四个系统,A 直接调用 BCD 三个系统的接口就 OK 了,但是你引入了一个 MQ,结果 MQ 挂了,搞得整套系统都不可用了。
- 系统复杂度提高
还是 ABCD 四个系统,本来是用的技术栈都蛮简单的,结果你引入了 MQ,导致经常会出现一些数据丢失、数据重复消费等奇奇怪怪的问题,导致系统的复杂度大大提高。
- 一致性问题
还是 ABCD 四个系统,本来 A 调用系统 BCD,调用 B 失败就不再调用系统 CD,直接回滚数据了。结果你引入 MQ,系统 A 把数据推送给 BCD 就直接返回成功了,但是只有 BC 消费消息成功了,系统 D 消费时写入失败了,你咋保证系统的数据一致性?
既然消息队列会产生这些问题,我们使用 MQ 的时候就必须要解决这些问题,否则,我们实际上是在给未来的自己挖坑。下面我列出几个常见的需要解决的消息队列问题:
- 如何保证消息队列的高可用?
- 如何保证消息不被重复消费?
- 如何处理消息丢失的问题?
- 如何保证消息的顺序性?
- 如何处理消息队列大量消息积压?
三、消息队列的选型
目前比较流行的消息队列中间件有:ActiveMQ、RabbitMQ、RocketMQ、Kafka。这里简单对比下不同的消息队列的优缺点:
- ActiveMQ:单机吞吐量:万级;时效性:毫秒级;可用性:高;消息可靠性:小概率丢数据;功能支持:极其完备
- RabbitMQ:单机吞吐量:万级;时效性:微秒级;可用性:高;消息可靠性:基本不丢;功能支持:erlang 开发
- RabbitMQ:单机吞吐量:十万级;时效性:毫秒级;可用性:非常高;消息可靠性:可配置 0 丢失;功能支持:分布式
- Kafka:单机吞吐量:十万级;时效性:毫秒级;可用性:非常高;消息可靠性:可配置 0 丢失;功能支持:分布式,一般配合大数据类的系统来进行实时数据计算、日志采集等场景,行业内的事实标准
通过以上的对比,ActiveMQ 现在使用得越来越少了,社区也不太活跃了;RabbitMQ 是开源的,也很稳定,社区也比较活跃,但是使用 erlang 开发,对公司来说不太可控,建议中小型公司使用;RabbitMQ 是使用 Java 开发的,社区相对比较活跃,对于公司也比较可控,毕竟能修改它的源码的大神也很多;Kafka 一般用在大数据领域的实时计算、日志采集等场景。
四、总结
本文介绍了消息队列的应用场景,并阐述了使用 MQ 的优缺点。对现在市面上比较流行的 MQ 做了个简单的对比,不同的 MQ 注重的点是不一样的。
作者:奈何花开
来源:https://xie.infoq.cn/article/84f9538c7468ed89434c68686
本文为原创文章,转载请标明出处。
本文链接:http://blog.fangzhipeng.com/javainterview/2021/05/14/a0bae95.html
本文出自方志朋的博客

(转载本站文章请注明作者和出处 方志朋-forezp)